mysql索引上之索引结构
前言
索引是数据库中最重要的概念之一,索引就像一本书的目录一样,可以让你快速的查询需要的信息。
索引结构
索引是一种数据结构,有助于查询的数据结构可以是Hash、有序数组、二叉树、B树等,具体mysql使用的是哪一种或哪几种呢,可以结合常用的使用场景分析下。
Hash结构
如果是Hash结构的,将索引列进行Hash后存储,当我们查询的时候,按hash查询会非常快(O(1)时间复杂度)。
但是Hash会有两个问题:
1、势必会出现Hash碰撞,当碰撞的数据过多时,查询的效率就会下降
2、对于mysql,经常会需要范围查询或排序,此时hash无法满足
所以Hash不适合做数据库的索引。
有序数组

如果索引选择有序数组,结构如上,那么对于查询和范围查询的表现都会非常优秀,因为有序的话可以使用二分查找,时间复杂度O(logn),还是不错的。
但是会面临插入耗时问题,对于插入一个数据,首先要找到插入的位置,再将其后面的所有元素后移一位,成本非常高。
所以有序数组也不适合做数据库索引,它比较适合静态数据存储,例如去年的某项排名等
二叉树结构
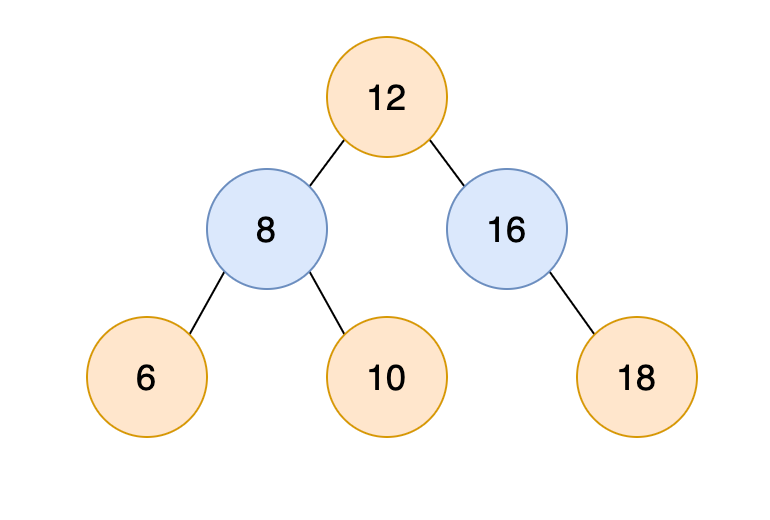
直接看二叉搜索树,左节点小于父节点,右节点大于父节点组成的二叉树是为二叉搜索树。二叉树对于查询速度如有序数组,平均时间复杂度O(logn)。
但是考虑一种情况,如果每次插入的数都比之前的大,那么二叉树便和有序列表一样,此时因为是树结构,所以需要一个个遍历,时间复杂度降到O(n);
另外,在数据量比较大的情况下,树高比较大,因为索引是放在硬盘的,那么就需要多次访问磁盘来搜索需要的数据。
针对树高的问题,就考虑使用多叉树了
InnoDb引擎的索引
拿InnoDB的索引举例,如果多叉树,每个节点存储1000条数据(InnoDB每页默认16k大小),树有4层的话,1000的3次方有10亿数据量,访问3次可以检索10亿数据量(索引顶层是放入内存中的)
所以一般多叉树会被选择作为数据库的索引存储结构,读写性能都有比较好的保障。在mysql中,索引是有存储引擎决定的,不同的搜索引擎可能有不同的索引结构,相同的索引结构在不同的引擎中的表现也可能不一样,下面主要会以常用的mysql InnoDB引擎的B+树展开。
B+树
使用 http://www.rmboot.com/BPlusTree.html 生成的3阶B+树如下:
在InnoDB中,每个索引都是一个B+树,InnoDB对经典B+树做了优化,叶子结点使用双向链表,提高区间访问性能,如下图:
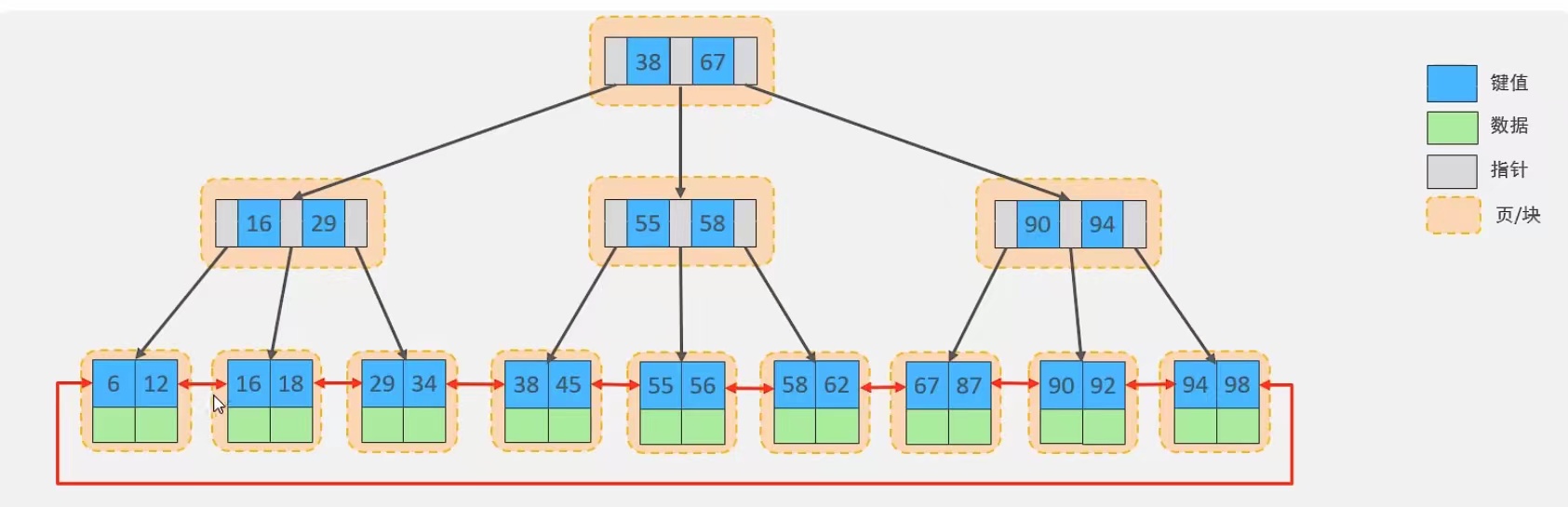
B+树有如下特点:
1、非叶子不存储数据,仅存储索引键值及指针
2、叶子节点包括所有的索引键值
3、仅叶子节点包括数据部分,且由双向指针链接
(对于叶子节点数据部分,如果是主键索引则数据是完整行数据,如果是二级索引则数据是主键索引的id)
B树
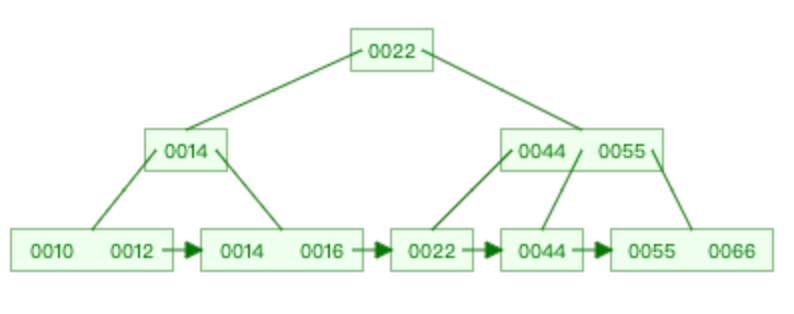
说到B+树,结合B树(也叫B-树)做个对比,B树的索引结构,如下图所示:
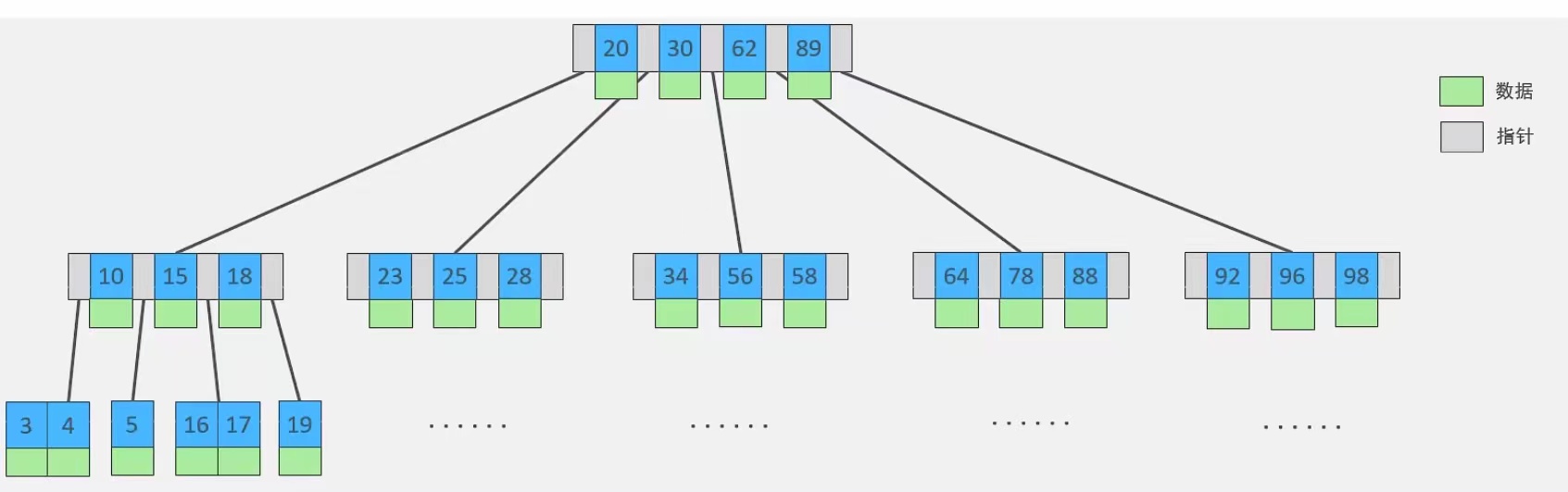
特点如下:
1、非叶子结点包括索引键值、指针及数据
2、叶子节点不包括全部数据
3、叶子节点没有链表关联
为什么InnoDB选择了B+树呢?通过特点可以发现:
1、B+树的非叶子结点,不包括数据部分,那么每页的可以存储更多的索引键值,树层级更少,搜索速度会更快。
2、叶子节点包括所有的索引键值和双向链表,可以更方便的范围查询。
所以InnoDB选择了B+树作为它的索引结构。
索引的维护
对于自增主键生成的主键索引(聚簇索引),主键自增,每次都是插入到树的最后,对于磁盘来说,属于追加操作,不需要挪动其它数据,也不会产生页分裂,速度是很快的。
而对于二级索引(非聚簇索引),插入的数据,如果不是顺序的,例如用户表的人名称,可能会导致数据页的分裂,插入性能会受到影响,且页分裂后页的利用率也会降低;当删除数据导致两个或多个页的数据比较少时,便会进行页的合并。
总结
InnoDB是索引组织表,采用的B+树作为索引结构,能够保障常见查询场景的查询速度和插入的速度。对不同数据结构经过很多方面的对比衡量,包括磁盘的读写机制、顺序插入、范围查询、索引键值存储、数据存储等。