mysql基础之一条查询SQL是如何执行的
背景
Mysql执行sql查询都经过了哪些内部步骤和验证,本篇做个简要的分析,当碰到一些异常和问题时能够更快的定位并解决。
执行流程
Mysql8.0版本后不再查询缓存
大概的执行步骤:
1、客户端发送一条查询语句到服务器;
2、服务器检验缓存,如果命中缓存,立刻返回结果;否则进入第3步;
3、服务器进行SQL分析、解析、预处理等,再到优化器确定执行计划;
4、根据执行计划调用引擎API接口查询数据;
5、返回结果,可以的话存入缓存。
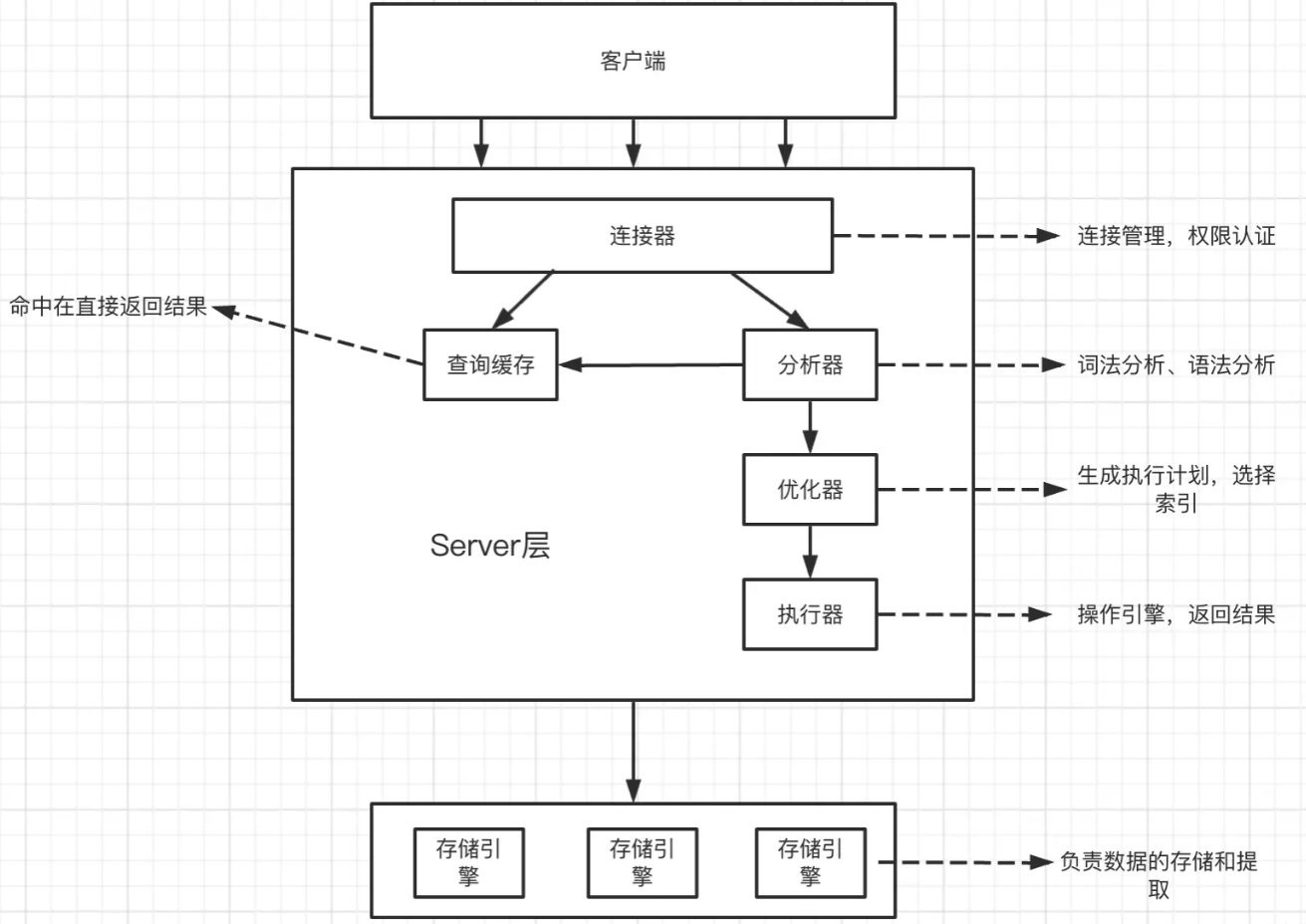
详细步骤
连接器
连接器主要用来管理客户端的连接。使用命令行连接,一般可以使用
-- 回车后输入密码
> mysql -h $ip -u$user -p
命令中mysql为客户端连接工具,此时会进行连接建立,完成TCP三次握手后,验证用户名与密码同时获取用户权限。
可以通过show processlist查看当前连接状态
连接后如果权限修改,需要重新连接;连接长时间无操作默认8个小时自动断开,通过wait_timeout参数控制。
缓存
如果是一条查询语句,则会先查询缓存,查询缓存是通过key-value的hash方式存储的sql与对应结果。
怎么判断是否查询缓存,Mysql是通过对sql语句大小写不敏感的检查sql是否以sel开头的,对于非sel开头的语句便不会走缓存。
查询缓存拿到结果后返回前会进行一次权限校验。
什么时候存入缓存呢?
当执行器获取到查询结果后,返回客户端时也会保存到缓存中,注意,当sql语句中有一些不确定的函数时,如now()等,该sql是不会进行缓存的。
使用查询缓存有利有弊
对于读多写少的情况,缓存效果好,利用率高;对于更新频繁的情况,每次更新都会清除该表的所有缓存,缓存利用率会非常低,得不偿失。
Mysql也提供了参数配置query_cache_type是否启用缓存,设置成DEMAND不使用缓存;也可以sql查询时使用sql_no_cache跟在select后面显示不使用。
Mysql8.0版本已经将缓存整个模块删掉了。
分析器
没有命中缓存的话,会进入分析器流程,进入真正的查询流程。分析器主要对sql进行词法分析与语法分析,知道sql做什么。
词法分析,分析语句的关键词,识别出表名,列名等;
语法分析,分析语句的语法是否正常,例如select…from…where 的结构。
如果分析器发现问题,会报错,关注报错信息紧跟着“use near”的提示,排查问题。
分析器完成后会进行一次权限校验,校验表、列是否存在。
优化器
经过了分析器后,知道了要做什么,到了优化器就要决定怎么做了。
优化器会根据表索引情况、数据长度、查询语句等等多维度决定如何查询能更快,更高效。
经过了优化器后就能确定如何查询,得到查询计划。
执行器
Msql通过分析器知道要做什么,通过优化器知道怎么做,到执行器就是真正的去执行查询结果了。
开始执行的时候,会判断是否有表查询权限,因为除了sql执行外,还可能有存储过程、触发器等,需要在此时校验,校验通过后打开表进行查询。
执行器与存储引擎的交互:
1、调用存储引擎API查询第一条数据,如果不是,跳过,如果是加入结果集(需要的话回表查询对应结果)
2、再次调用存储引擎API获取下一条数据,重复判断,直到最后一条数据
3、将结果集进行返回客户端(如果需要排序之类的,会在此排序)
存储引擎
存储引擎可以理解为数据库的插件,包括有InnoDB、MyISAM、Memory等多个引擎,提供了API供上层使用。
Mysql5.5之后默认使用的是InnoDB,它特有的特性支持行锁、事务、外键。在创建数据库时,也可以通过如engine=memory进行指定其它存储引擎。
总结
1、执行一共涉及到4处权限校验。连接时校验用户名密码,数据库实例权限校验;缓存查询到时做一次权限校验;分析器分析完成后进行一次校验,表列是否存在;执行器执行之前进行最后一次校验,表权限等。
2、如果查询走二级索引,需要返回的数据在主键索引中,则每一行结果都会进行回表查询。