redis之哨兵模式搭建
前言
闲暇之余,搭建了个redis的哨兵系统。
针对,redis的主从虽然能保证数据的冷备份,方便进行故障恢复,或者主从实现读写分离,能够负载读压力,但是存在一个问题是:故障恢复无法自动化,因为有了哨兵,进一步提高系统的可用性。
作用
1、监控:检测主、从节点是否正常
2、自动故障恢复
3、配置提供者:给客户端使用时,可以用哨兵获取主节点地址(注意是提供配置,方便故障转移时自动链接,而非代理)
4、通知:将故障转移结果发给客户端
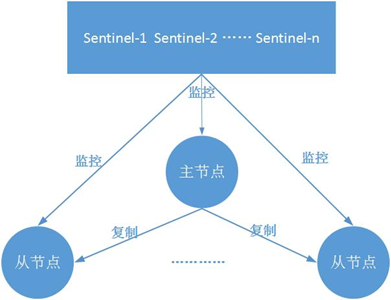
架构
这里搭建仅用了一个sentinel
哨兵节点是一种特殊的redis节点。
部署
| 服务 | 名称 | 端口 |
|---|---|---|
| 主节点 | master | 6379 |
| 从节点 | slave1 | 6378 |
| 从节点 | slave2 | 6377 |
| 哨兵节点 | sentinel | 26379 |
配置
1、主节点
关键配置:redis.conf
logfile "/var/log/redis/redis-server.log"
pidfile "/var/run/redis/redis-server.pid"
port 6379
bind 0.0.0.0
dbfilename "dump.rdb"
masterauth "XXX"
requirepass "XXX"
2、从节点1
关键配置:slave1.conf
logfile "/var/log/redis/redis-server-slave1.log"
pidfile "/var/run/redis/redis-server-slave1.pid"
port 6378
bind 0.0.0.0
dbfilename "dump-slave1.rdb"
slaveof 127.0.0.1 6379
masterauth "XXX"
requirepass "XXX"
3、从节点2
关键配置:slave2.conf
logfile "/var/log/redis/redis-server-slave2.log"
pidfile "/var/run/redis/redis-server-slave2.pid"
port 6377
bind 0.0.0.0
dbfilename "dump-slave2.rdb"
slaveof 127.0.0.1 6379
masterauth "XXX"
requirepass "XXX"
4、哨兵节点 sentinel
daemonize yes
pidfile "/var/run/redis/redis-sentinel.pid"
logfile "/var/log/redis/redis-sentinel.log"
port 26379
# 监控命名为mymaster的主节点,ip + 端口 + 1(数字1表示故障转移时,至少需要多少个哨兵节点同意,才能判定主节点故障并进行故障转移,从主观变客观下线,一般哨兵节点一半加1个。)
sentinel monitor mymaster 127.0.0.1 6379 1
sentinel auth-pass mymaster XXX
启动
依次执行如下启动命令:
主节点:systemctl start redis-server
从节点1:redis-server /etc/redis/slave1.conf
从节点2:redis-server /etc/redis/slave2.conf
哨兵:systemctl start redis-sentinel
启动后执行命令如下所示: ps -ef | grep redis

连接sentinel:redis-cli -p 26379
执行命令:info Sentinel
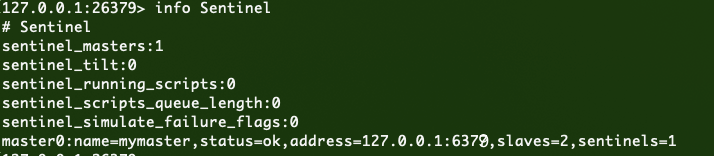
根据最后一行:master0:name=mymaster,status=ok,address=127.0.0.1:6379,slaves=2,sentinels=1
监听1个名为mymaster的主机节点,同时有2个从节点,1个sentinel
查看连接从节点的状态,执行命令:sentinel slaves mymaster
7) "runid"
8) "6582ade03ccd6efaec657c633dcb8602acd01680"
9) "flags"
10) "slave"
关注这几行,可判断是否正常。
演练故障
主节点故障
执行命令:systemctl stop redis-server
观察sentinel日志:
// +sdown 主节点进入主观下线状态
29994:X 10 Oct 21:50:01.572 # +sdown master mymaster 127.0.0.1 6379
// +odown 客观下线,真正下线(经由1/1个哨兵投票)
29994:X 10 Oct 21:50:01.572 # +odown master mymaster 127.0.0.1 6379 #quorum 1/1
// 哨兵检查出故障,+new-epoch加1,从0变成1
29994:X 10 Oct 21:50:01.572 # +new-epoch 1
29994:X 10 Oct 21:50:01.572 # +try-failover master mymaster 127.0.0.1 6379
// 投票选举哨兵领导者
29994:X 10 Oct 21:50:01.575 # +vote-for-leader ae794ad42657621e4811436c1445a0b17c91ce8a 4
// 哨兵领导者选择完成
29994:X 10 Oct 21:50:01.575 # +elected-leader master mymaster 127.0.0.1 6379
// 准备故障转移,选择新的从节点
29994:X 10 Oct 21:50:01.575 # +failover-state-select-slave master mymaster 127.0.0.1 6379
// 故障切换,选择slave2,对应端口为6377的从节点做主节点
29994:X 10 Oct 21:50:01.675 # +selected-slave slave 127.0.0.1:6377 127.0.0.1 6377 @ mymaster 127.0.0.1 6379
// slave2执行slaveof-noone,从从节点变成主节点
29994:X 10 Oct 21:50:01.675 * +failover-state-send-slaveof-noone slave 127.0.0.1:6377 127.0.0.1 6377 @ mymaster 127.0.0.1 6379
29994:X 10 Oct 21:50:01.737 * +failover-state-wait-promotion slave 127.0.0.1:6377 127.0.0.1 6377 @ mymaster 127.0.0.1 6379
// 从节点成功变成主节点
29994:X 10 Oct 21:50:01.792 # +promoted-slave slave 127.0.0.1:6377 127.0.0.1 6377 @ mymaster 127.0.0.1 6379
// failover状态变为reconf-slaves
29994:X 10 Oct 21:50:01.792 # +failover-state-reconf-slaves master mymaster 127.0.0.1 6379
// 领导者将其它从节点,指向新的主节点
29994:X 10 Oct 21:50:01.851 * +slave-reconf-sent slave 127.0.0.1:6378 127.0.0.1 6378 @ mymaster 127.0.0.1 6379
29994:X 10 Oct 21:50:02.842 * +slave-reconf-inprog slave 127.0.0.1:6378 127.0.0.1 6378 @ mymaster 127.0.0.1 6379
29994:X 10 Oct 21:50:02.842 * +slave-reconf-done slave 127.0.0.1:6378 127.0.0.1 6378 @ mymaster 127.0.0.1 6379
29994:X 10 Oct 21:50:02.904 # +failover-end master mymaster 127.0.0.1 6379
// 转移结束,6377成为新的主节点
29994:X 10 Oct 21:50:02.904 # +switch-master mymaster 127.0.0.1 6379 127.0.0.1 6377
// 6378从节点,成为 6377的从节点了。
29994:X 10 Oct 21:50:02.904 * +slave slave 127.0.0.1:6378 127.0.0.1 6378 @ mymaster 127.0.0.1 6377
// 原主节点6379 成为 6377的从节点了。
29994:X 10 Oct 21:50:02.904 * +slave slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6377
新的环境:哨兵新的info信息

注意
1、哨兵在进行故障转移时,会进行原从节点重新配置,主要为slaveof的改变,并修改到.conf中。但不会修改masterauth,所以可能导致故障转移后,从节点无法连接到新的主节点上,报错:
22542:S 10 Oct 20:57:33.658 * MASTER <-> SLAVE sync started
22542:S 10 Oct 20:57:33.658 * Non blocking connect for SYNC fired the event.
22542:S 10 Oct 20:57:33.658 * Master replied to PING, replication can continue...
// 如,主节点设置密码,从节点未设置密码(requirepass)的情况下,
// 从节点会配置masterauth;故障转移后,新的主节点是没有requirepass的,导致从节点连接新的注解点会报错。
22542:S 10 Oct 20:57:33.659 # Unable to AUTH to MASTER: -ERR Client sent AUTH, but no password is set
所以:需要将原主节点和从节点都配置相同的requirepass和masterauth。或者都不配置(不太安全)
2、在哨兵节点启动和故障转移阶段,各个节点的配置文件会被重写(config rewrite)
3、哨兵系统的主从节点,和正常的主从无区别,主要是加入了哨兵这个特殊的redis节点,帮助故障的检测和自动转移。
另外,例子中,一个哨兵只监控了一个主节点;实际上,一个哨兵可以监控多个主节点,通过配置多条sentinel monitor
原理
流程
1、redis使用一组sentinel节点监听主从节点的可用性
2、一旦监听到主节点失效,将会从哨兵节点中选一个领导者
3、哨兵领导者来选择从节点作为新的主节点
如何监控
sentinel有3个定时任务检测redis节点可用性:
1、每隔10秒,向主从节点发送info命令,获取redis拓扑结构信息,包括主从角色,IP,端口。
2、每隔2秒,向sentinel:hello频道同步自身sentinel得到的主节点信息及当前哨兵节点的信息,同时可传达给其它哨兵节点当前获取的信息。
3、每隔1秒,向主从节点和其它哨兵节点ping命令,检测节点的状态
心跳检测
如果ping命令无法在固定的时间内(down-after-milliseconds)响应或返回错误的回复,那么会判断该节点(主从/哨兵)主观下线 sdown。
主观下线(sdown):心跳检测失败则认为节点主观下线
客观下线(odown):指针对主节点,当一个哨兵任务主节点主观下线时,会通过命令(sentinelis-master-down-byaddr)询问其它哨兵节点主节点的状态,超过一定数量的哨兵节点认为主节点下线了,则此时对主节点进行客观下线
选举一个sentinel作为领导者
当主节点客观下线后,会在sentinel中选择一个节点作为领导者,收到半数以上的节点同意即可
选择新的主节点
过滤掉不健康的从节点,由领导者从健康的从节点中选择一个新的主节点。(要么slave-priority最高,要么复制偏移量最大,要么就是runId最小,一层层筛选)
执行failover切换
领导者向选择的从节点发送slaveof no one提升其为主节点。
然后向其它从节点发送slaveof命令使其成为新的主节点的从节点,原来的主节点更新为新的从节点(启动后链接新的主节点)。