性能压测知多少
前言
接口或服务压测,是新功能或服务上线前必做的事情,我们的接口或服务能承担多大的压力,需要做到心中有数,以根据用户量进行节点的部署,这样才能放心的将其发布线上接收真实用户的洗礼。
压测关注指标
QPS(TPS):每秒处理的请求/事务数量。
并发数:同时在线用户数或需要同时处理的请求/事务数。
响应时间:请求的响应时间,包括平均响应时间,TP90、TP95、TP99等。
TP(Top Percentile):如TP90,表示90%的请求小于某个时间。
一般QPS会作为衡量系统吞吐量的关键指标,当然还和系统的CPU、内存、IO、带宽等有密切关系。
不严格的计算公式:QPS = 并发数 / 平均响应时间
例如:
在食堂打饭时,如果有10个窗口,平均每个人打饭需要10s钟,那么可以用下面的方法计算:
并发数 = 10个窗口;
平均响应时间 = 10s;
QPS = 10个 / 10s
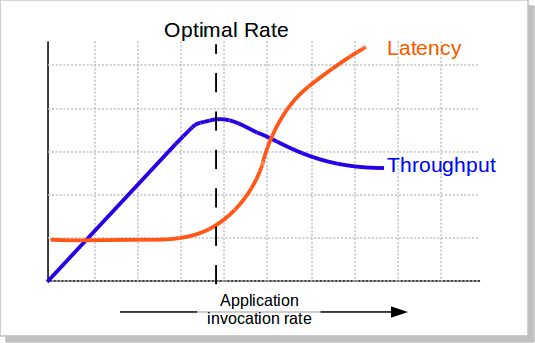
当请求量慢慢增加时,系统吞吐量便不会再上涨,继续增加的话,反而会因为系统资源满负荷运行,导致吞吐量下降,因为内存回收、线程上下文切换都需要cpu资源。
网上找了个吞吐量等受并发数影响的关系图:
一些注意点
在做性能压测需要我们注意以下几个点:
不止关注平均响应时间
平均响应时间并不是很靠谱,例如压测10次请求,其中9次1s、1次9s,那么平均响应时间就是2s,其实9s属于不正常的值,属于噪音,应该去掉。
可以关注另外两个时间:
1、中位数:会比平均值好一些,将一组数据按从小到大排列,中间那个数便是中位数,意味着有50%的请求低于或高于该中位数。
2、TP(Top Percentile),更为准确,TP90:表示90%的请求响应时间都小于某个值;
比如:有一组测试时间:【1ms,100ms,20ms,200ms】,从小往大排列得到:【1ms,20ms,100ms,200ms】,那么TP90的请求时间等于ceil(4*0.9)=200ms(4表示数据的大小)。
同时关注吞吐量QPS和时间
如果系统只看吞吐量和并发数,不管响应时间是没有意义的,哪怕系统QPS能达到10万,响应超过3,5分钟,那么系统已经算是不可用了,此时的吞吐量是没有意义的。
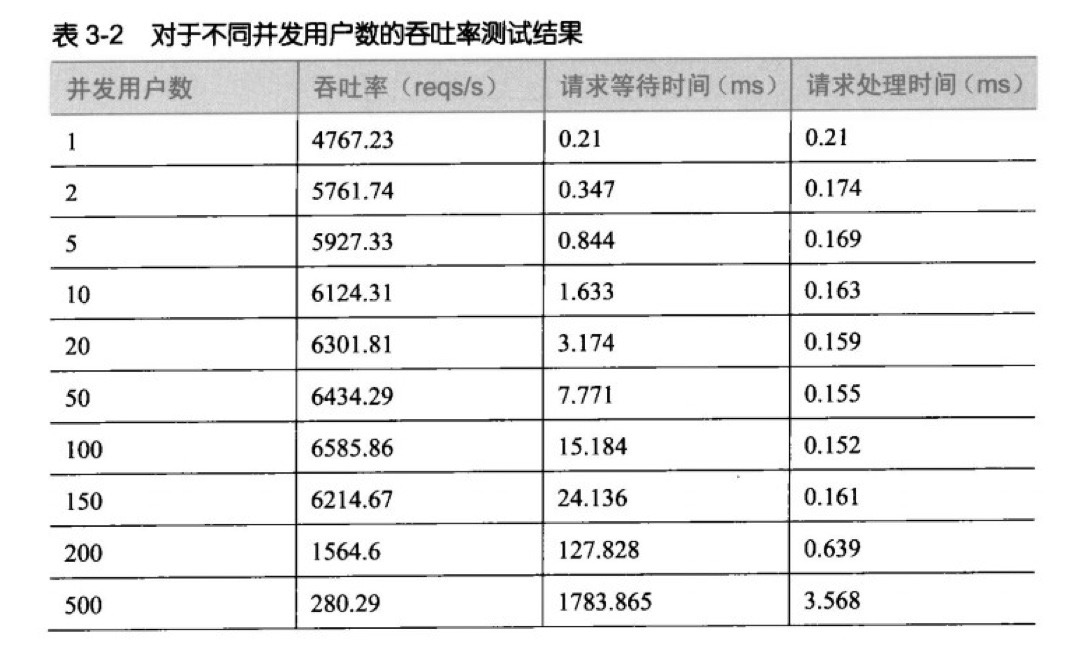
当并发数上升时,系统会慢慢变得不稳定,响应时间也会随之波动,包括cpu和内存等也会变动,如下:
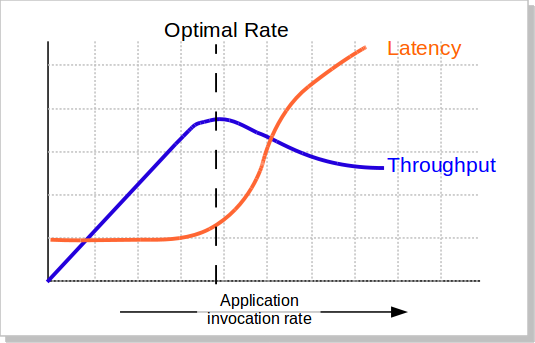
Latency:响应时间
Throughput:吞吐量
随着并发量上升,吞吐量慢慢升到到一定值后,不会继续升反而会下降,此时响应时间也会上升,系统处于不稳定状态。
所以,需要我们确认系统响应时间上限,然后找到系统可能承担的最大吞吐量。
需要关注成功率
如果请求不成功,那么压出来的性能是没有意义的,用户请求都不成功了,再大的吞吐量也没用。
对于一些关键服务,需要我们压测的成功率达到100%。
压测需要持续一段时间
压测需要持续一段时间,进行不同数据,不同时长的压测,不能是两三分钟压一压,得出什么结论,特别是刚启动的服务,可能一些连接池需要进行初始化、数据是否进缓存等等,都会影响我们的压测结果。
持续压测期间,关注各项服务器指标,如CPU、内存、gc情况、线程、网络IO、缓存IO、数据库等等,进而进行针对性的优化。
压测工具 JMeter
在使用JMeter图形化界面进行压测时(具体使用方式可以自行Google),压测结果的统计,使用 Add -> Listener -> Aggregate Report。
该报告支持中位数、TP90、TP95等等数据,更清晰的反映出压测情况,如下:

如何更好的压测
一般压测来说,需要拿到以下几个指标:吞吐量Thoughtput、响应时间Latency、资源利用率(CPU、内存等)、成功率等。
1、首先定一个系统响应时间,如TP99和成功率。
比如TP99 50ms、成功率100%
2、然后在这个响应时间要求下,压出一个最高吞吐量。
3、使用该吞吐量,继续压测一段时间,观察系统的稳定性,收集CPU、内存、网络IO等等指标,如果cpu和内存都是平稳的,那么这个就是系统的性能。
基于这个吞吐量,将其乘以70%作为系统的报警线。
4、找到系统的极限值,如,在成功率100%的情况下(不考虑响应时长),系统能坚持多久,作为系统的峰值。
5、做Burst Test,用第2步的稳定吞吐量和第4步的极限吞吐量,来回压测,持续一段时间,观察系统的稳定性指标。
总结
压测不仅仅是这些,还有很多需要慢慢的考虑和总结,如模拟数据量、数据的有效性等等,我们不能模拟用户,用户是没有章法的,我们能做的就是要摸到系统的压力线,然后提高并保护这条线。