延迟双删的第一次删除有意义吗?
前言
在使用缓存的时候,如何做到数据库与缓存数据的一致性,是至关重要的,最终一致性是一种比较推崇的模式。一致性的策略有很多,延迟双删策略,便是策略之一,它有哪些需要我们了解的呢。
关于一致性
数据库层和缓存层的一致性通常也叫双写一致性,在分布式系统中,一致性会分为:强一致性、弱一致性。
强一致性:写入数据后,读取的就是最新的数据。可以通过2PC或者分布式锁来保障,对性能有影响。
弱一致性:不要求写入的新数据多久能读到,尽可能保证在一段时间内被读取到,弱一致中有一个业内熟知的模型叫最终一致性。确保数据在一定时间内是达到一致的状态。大部分场景使用最终一致性即可,在少数场景需要做到强一致性,如库存这种敏感有限的资源使用上。
延迟双删对与错
缓存模型
Cache-Aside,是应用比较广泛的一种缓存模型,也叫旁路缓存模型。
该模型的逻辑如下:
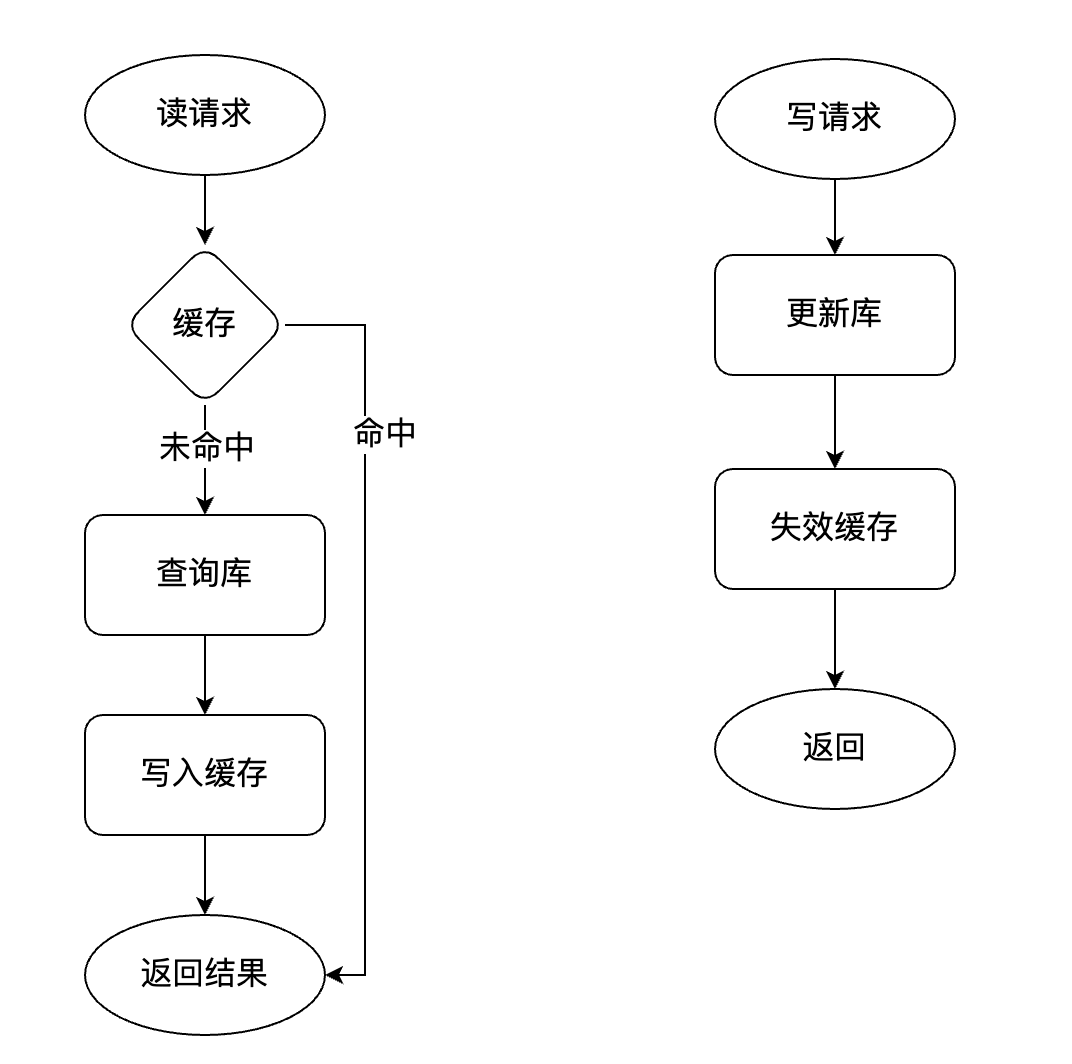
失效缓存,而不是更新缓存,为了防止并发写导致更新缓存旧数据。
这个模式也会发生数据不一致的情况,例如:
读线程A在读数据,缓存失效,读到数据库后;此时写线程B更新数据,更新完数据库,删除缓存;此时读线程A写缓存,便会将之前读到的旧值写到缓存中,导致数据的不一致。
但实际上出现的概率比较低,首先读线程读时缓存要失效,其次读请求慢于写请求,正常写请求会锁行,也会比读慢些,所以出现的概率低。
延迟双删
所以针对上面的模式,衍生出来延迟双删来解决某些场景下数据不一致的情况。
所谓延迟双删,网上最多的一种说法是:当处理更新请求时
1、先删除缓存(第一次删除)
2、更新数据库
3、sleep一会(具体一会是多久,结合查询场景的时长决定)
4、再次删除缓存
延迟双删真的万无一失了吗(情况1)?
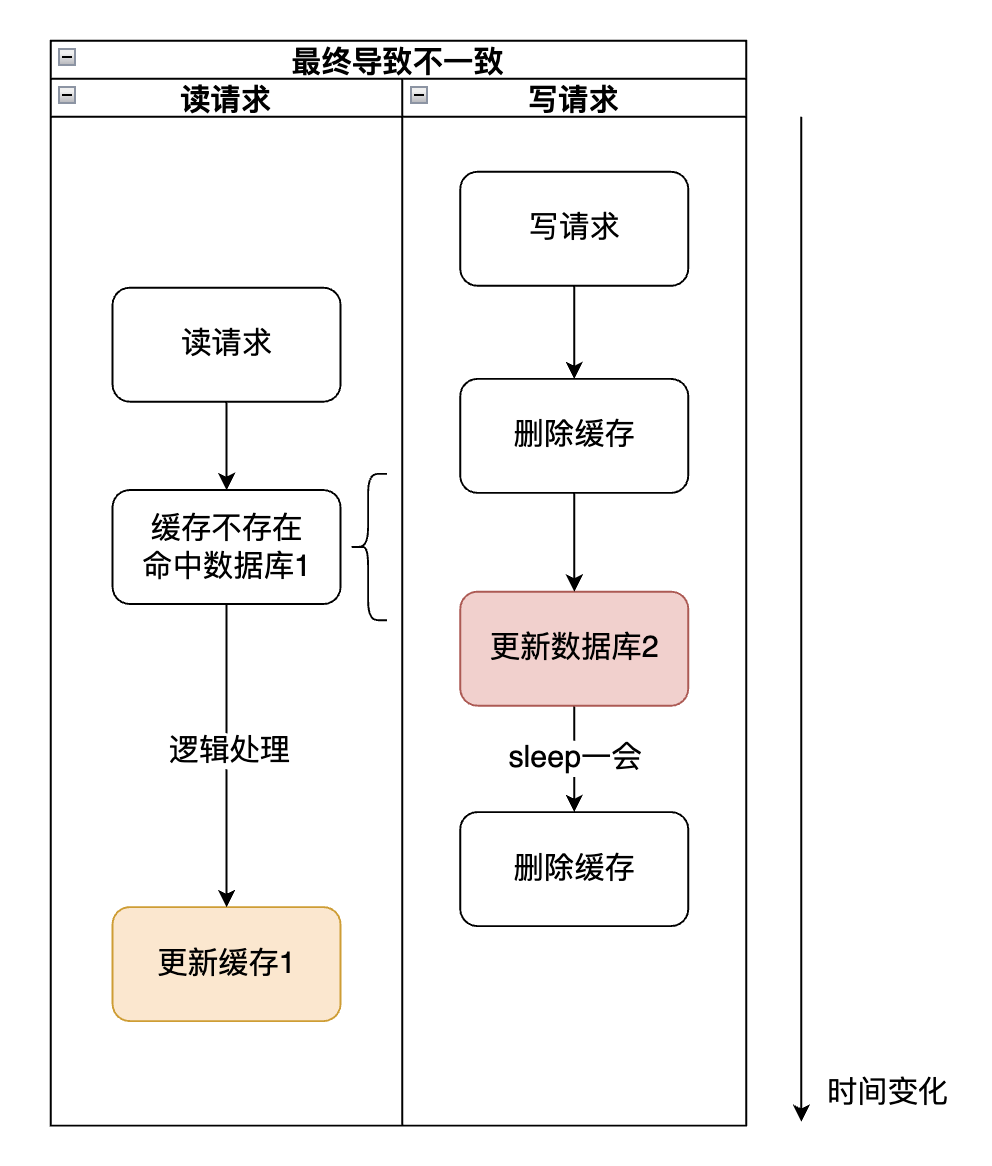
该情况的发生,出现在读请求发生在写请求第一次删除缓存与更新数据库之间,然后读请求将缓存写入是在写请求延迟删除之后。
再来看另一种情况(情况2):
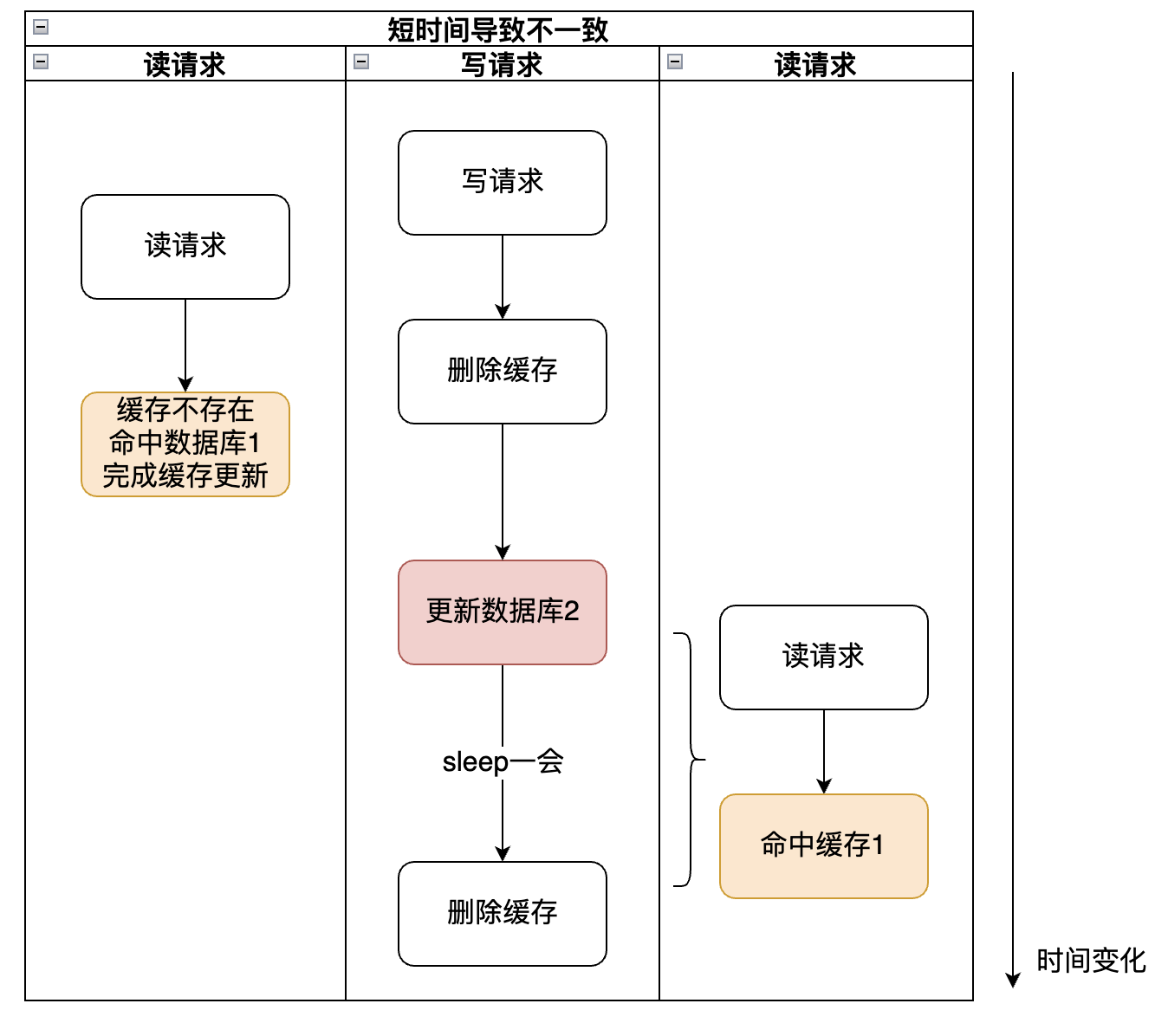
如果并发稍微高一点,便会出现上面的情况,第二个读请求仍然读到的是旧缓存数据,这时候第一次删除缓存没意义。
那么问题来了,为什么还要进行第一次删除缓存呢?
带来的可能好处:
1、先进行删除缓存,为了防止更新数据库后,删除缓存失败。
2、如果写请求在删除缓存,更新完数据库后,这时候有读请求进来,就可以读取到最新的数据。
对于1造成删缓存失败的原因,可能是服务突然宕机或者缓存连接等问题。这是个及其低概率事件,在日常服务发布都会采用滚动式发布,先阻断流量;缓存删除失败,还有第二次延迟删除,第二次也失败,这时候需要人工介入了。
对于2也是个低概率事件,不过算是一个好处。
带来的问题:
1、可能造成上面说的最终不一致的情况,见情况1。(先删提高了这个概率,默认是缓存自动过期时才会查库,现在更新前先删缓存就会增加这个概率)。
2、对于读多写少的场景,删完缓存,立马又会将旧数据写入,见情况2。缓存就是为了在读多写少的场景下加快查询速度,所以第一次删除没有意义了。
3、特别注意,一般更新操作都会有事务,代码执行完后才会进行提交,如果延迟删除不进行异步,那么就会导致其实2次删除缓存都是在数据更新之前进行的。
综上:
第一删除是没有什么意义的,反而增加了一个致命的问题,就是最终不一致的概率。
更好的建议,看你的场景:
1、如果是需要保证强制一致性的,使用分布式锁或分布式事务,少部分场景。
2、如果追求持续的查询速度,可以只使用延迟删除,注意延迟删除需要异步。
3、如果追求尽快拿到最新的数据,缩短不一致的时间,建议更新数据库后,进行一次删除,再延迟删除一次。
如下图所示:
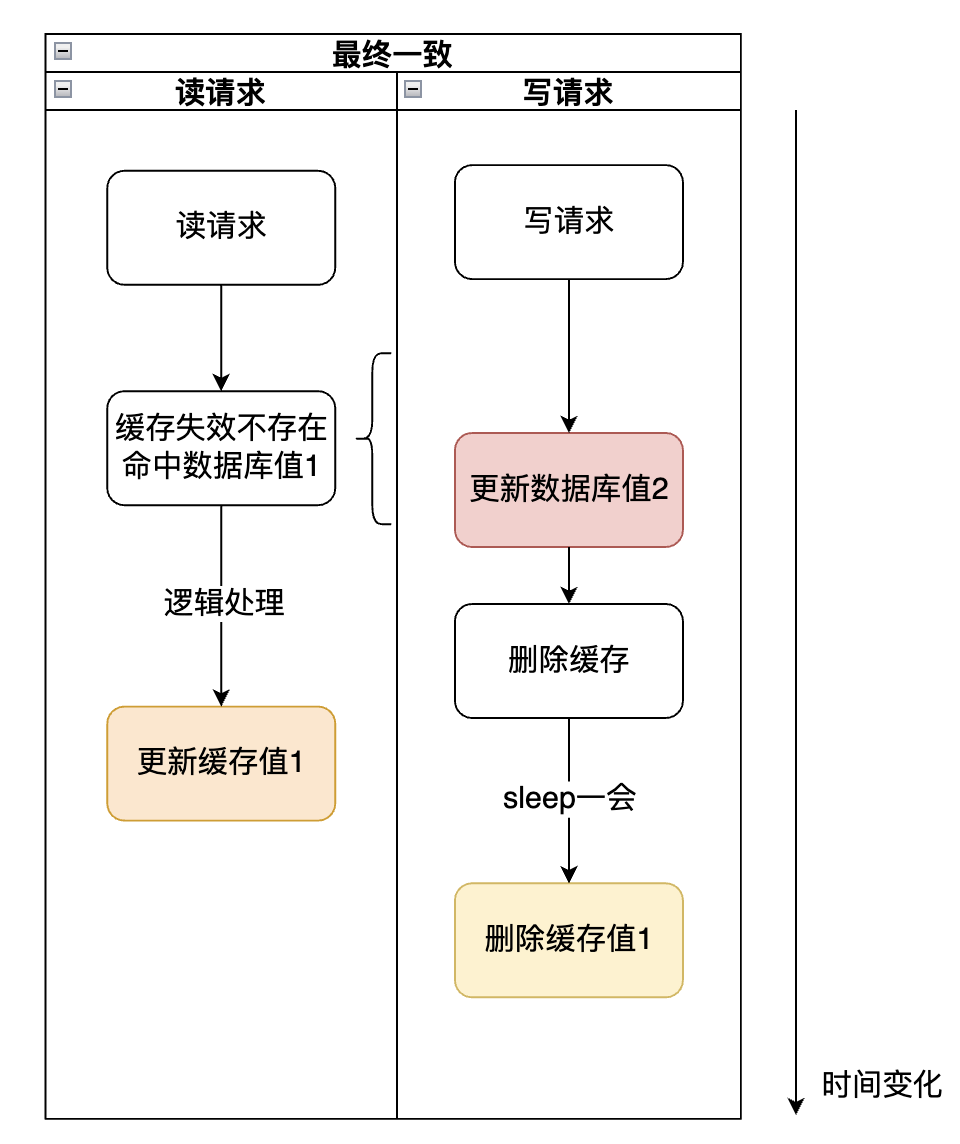
2,3适合大部分场景,选一种实现即可;
在2,3的实现上,注意事务对于更新数据库和删除缓存两个步骤顺序的影响,因为删除缓存的时间远小于更新数据库。
延迟删除的方式
1、采用消息队列,使用带延迟消费的mq中间件;借助存储和重试机制达到最终一致性目的。
2、采用本地线程池,不用引入外部组件,使用定时执行任务的线程即可,但是不能进行消息存储和重试。
3、采用binlog订阅,不用侵入业务代码,是一种更加优雅的方式。一个比较成熟的方案是canal(模拟Mysql的 slave交互协议,订阅binlog,canal也支持把订阅记录发送到mq中,如Kafaka和RocketMq);或者使用云产品,如阿里云DTS订阅等。
总结
介绍了缓存常见的模型,Cache-Aside模型,大部分场景只需要保证缓存的最终一致性即可。
进一步分析了延迟双删的第一次删除的意义,其实是没什么意义的;同时提到一些注意事项,特别是事务存在时,删除缓存和更新数据库的时序问题,需要特别注意,可以通过AOP、异步等进行处理。